
In Operation
Here’s an image of Gespeaker in action.
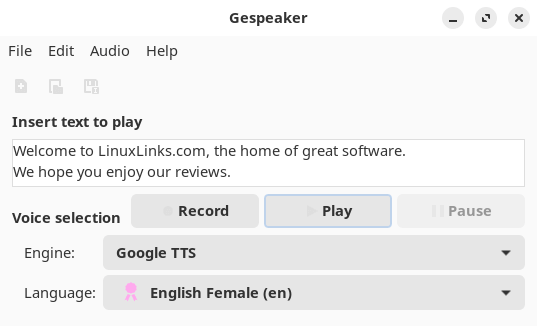
It sports a very simple interface. We can enter text or load a text file. Then choose the engine, and the voice. In the image above, we’re not using the eSpeak engine, but Google TTS instead.
There isn’t recording functionality, so we captured the output with Audacity, a popular audio editing and recording app.
Here’s the output with Google TTS engine. It sounds pretty good although somewhat laboured.
Here’s the output with the eSpeak engine. It sounds very robotic in comparison.
The next two samples are from Google TTS, and eSpeak engine respectively. The third sample is from Tortoise, software which uses deep learning.
Google TTS engine
eSpeak engine
Tortoise engine with high quality preset
The quality from Tortoise is head and shoulders better, even though pronunciation of the names of Linux distros is not handled well compared to Google TTS or eSpeak.
Summary
Gespeaker is a very simple frontend. It supports a few engines, but the quality of the generated speech is significantly worse than samples generated with equivalent software that uses deep-learning such as Tortoise or TTS. But that’s not really a criticism of Gespeaker.
We’d love the project to add support for Tortoise or TTS.
Recording functionality is not yet implemented.
eSpeakNG (Next Generation) is a continuation of the original developer’s project with more feedback from native speakers. Unfortunately, Gespeaker doesn’t support eSpeakNG.
Website: www.muflone.com/gespeaker
Support: GitHub Code Repository
Developer: Fabio Castelli
License: GNU General Public License v3.0
Gespeaker is written in Python. Learn Python with our recommended free books and free tutorials.
Pages in this article:
Page 1 – Introduction and Installation
Page 2 – In Operation and Summary