
In Operation
Start Ultimate Vocal Remover with the command:
$ python UVR.py
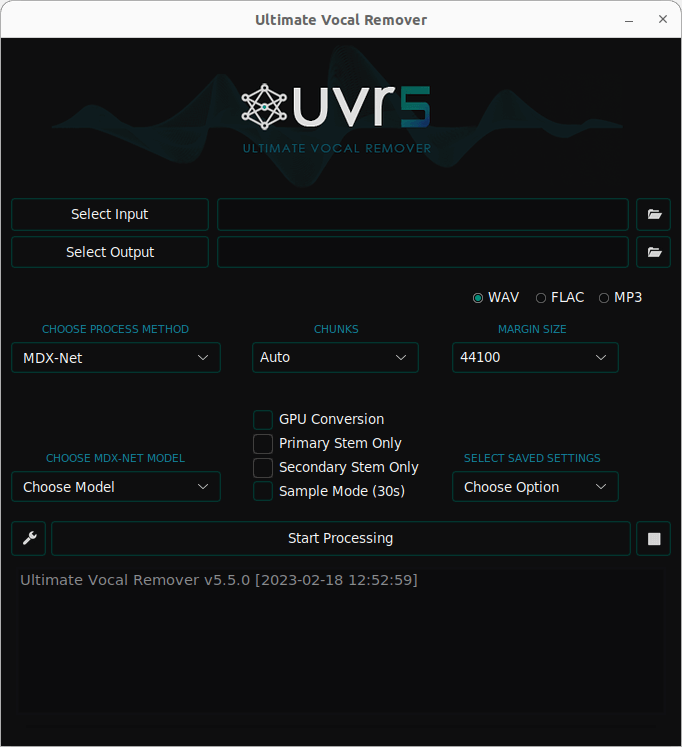
Start by selecting your input and output. On our system, directories and files are blanked out in the dialog boxes. But you can see files and directories by clicking the blank entries. We can save the output to WAV, FLAC, and MP3 formats.
The process method dropdown offers different processing methods. These methods create a system able to perform audio source separation. Such a system, given an audio signal as input will decompose it in its individual parts.
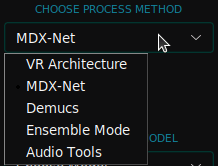 VR Architecture
VR Architecture- MDX-Net
- Demucs – this is based on a U-Net convolutional architecture inspired by Wave-U-Net. The v4 version features Hybrid Transformer Demucs, a hybrid spectrogram/waveform separation model using Transformers.
- Ensemble Mode – In this mode you need to select 2 or more models to save an ensemble. You can choose the following the stem pair:
- Vocals/Instrumental;
- Other/No Other;
- Drums/No Drums;
- Bass/No Bass;
- 4 Stem Ensemble
- Audio Tools:
- Manual Ensemble;
- Align Inputs.
The interface lets you download models for the three processing methods: VR Arch, MDX-Net and Demucs. For example, for Demucs, you can download different models for v1, v2, v3 and v4 including the 6 stem model.
Additional models and application patches can be downloaded via the “Settings” menu within the application.
You’ll want to check GPU Conversion.
Summary
Ultimate Vocal Remover GUI offers easy access to a wide range of models all accessible from a convenient GUI. The tool gets our recommendation even though it’s not the most intuitive. For example, to get an instrumental file (i.e. without vocals), you first need to choose Vocals as the stem, and then tick the Instrumental Only box.
There are lots of advanced options available from the small spanner icon which is adjacent to the Start Processing button.
While the project provides binaries for macOS and Windows, this isn’t the case for Linux. We appreciate that providing distro-specific packages for Linux distros is somewhat challenging. But we’d love to see a cross-platform package such as an AppImage available. Because as things stand, installing the software in Linux isn’t that user-friendly. And that’s a shame because this GUI is definitely worth installing.
You’ll need a powerful GPU as the models used are computationally intensive. We tested the software using a mid-range GeForce RTX 3060 Ti with 8GB of VRAM. That’s the minimum amount of RAM the project recommends. There’s currently no support for AMD Radeon GPUs.
Many of the models are trained by the developers of the project.
We didn’t investigate to any extent why folders and directories are blanked out. If you have a fix for this issue, do drop a comment below.
Website: ultimatevocalremover.com
Support: GitHub Code Repository
Developer: Anjok07, aufr33
License: MIT License
Ultimate Vocal Remover GUI is written in Python and Tcl. Learn Python with our recommended free books and free tutorials. Learn Tcl with our recommended free books and free tutorials.
![]() For other useful open source apps that use machine learning/deep learning, we’ve compiled this roundup.
For other useful open source apps that use machine learning/deep learning, we’ve compiled this roundup.
Pages in this article:
Page 1 – Introduction and Installation
Page 2 – In Operation and Summary