
Natural language processing (NLP) is a field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human (natural) languages. It includes word and sentence tokenization, text classification and sentiment analysis, spelling correction, information extraction, parsing, meaning extraction, and question answering.
In our formative years, we master the basics of spoken and written language. However, the vast majority of us do not progress past some basic processing rules when we learn how to handle text in our applications. Yet unstructured software comprises the majority of the data we see. NLP is the technology for dealing with our all-pervasive product: human language, as it appears in social media, emails, web pages, tweets, product descriptions, newspaper stories, and scientific articles, in thousands of languages and variants.
Many challenges in NLP involve natural language understanding. In other words, computers learn how to determine meaning from human or natural language input, and others involve natural language generation.
There are some excellent open source software to solve common problems in text processing like sentiment analysis, topic identification, automatic labeling of content, and more.
To provide an insight into the quality of software that is available, we have compiled a list of 16 excellent open source NLP tools. Hopefully, there will be something of interest here for anyone who wants to use these tools to solve practical problems. Our recommendations are captured in a legendary LinuxLinks-style ratings chart.
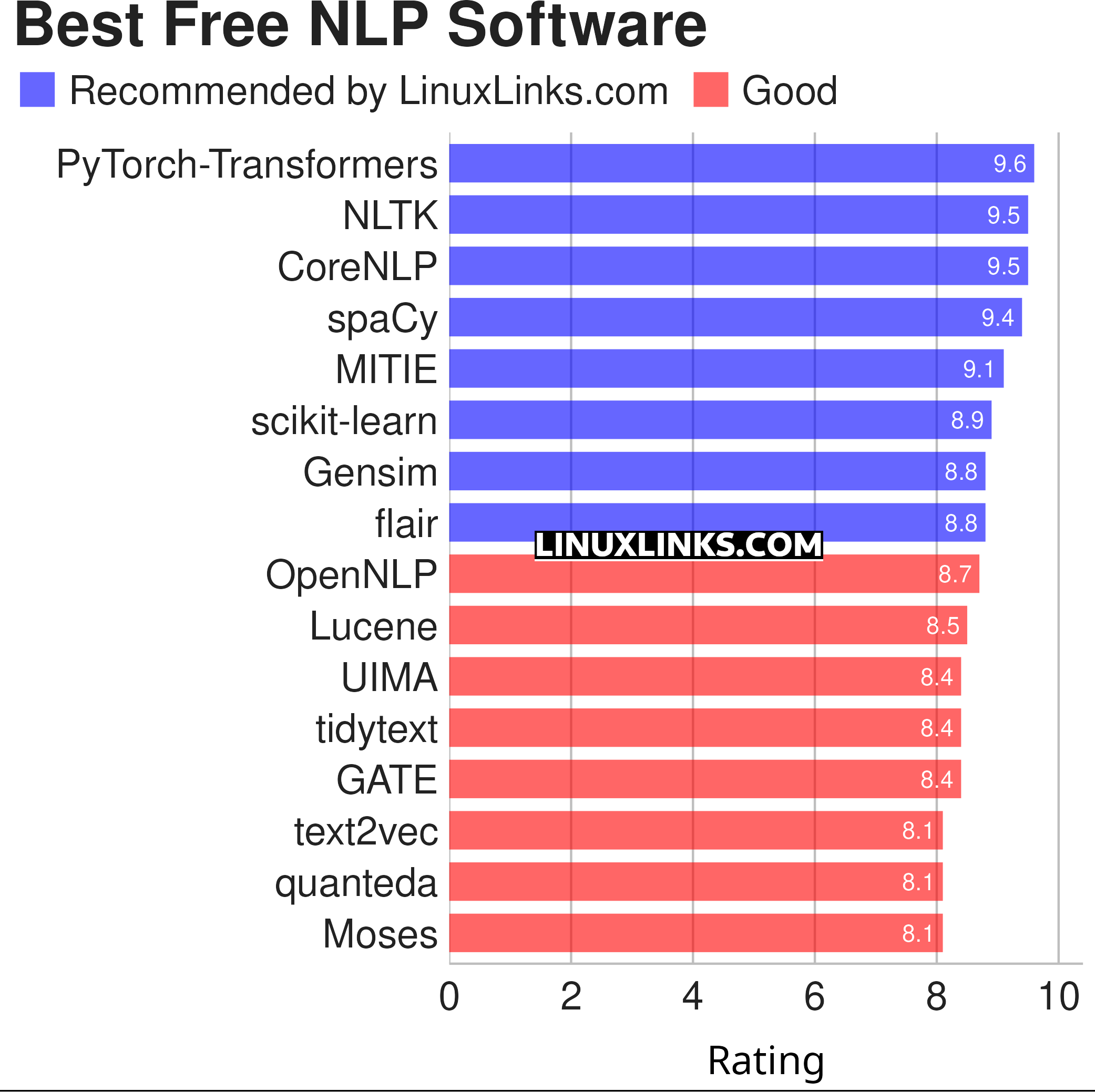
Click the links in the table below to learn all about each tool.
| Natural Language Processing | |
|---|---|
| PyTorch-Transformers | Library of state-of-the-art pre-trained models |
| Natural Language Toolkit | Suite of open source Python modules, data sets and tutorials |
| Stanford CoreNLP | Extensible annotation-based NLP pipeline |
| spaCy | Industrial strength natural language processing |
| MITIE | MIT Information Extraction |
| scikit-learn | Machine learning library for Python |
| Gensim | Python-based vector space modeling and topic modeling toolkit |
| flair | Simple framework for state-of-the-art NLP |
| Apache OpenNLP | Machine learning based toolkit |
| Apache Lucene | Full-featured information retrieval software library |
| UIMA | Implementation of the UIMA specification |
| tidytext | Text mining using dplyr, ggplot2, and other tidy tools |
| GATE | General Architecture for Text Engineering |
| text2vec | Framework with API for text analysis and NLP |
| quanteda | R package for Quantitative Analysis of Textual Data |
| Moses | Statistical machine translation system |
This article has been revamped in line with our recent announcement.
 Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category. Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category.This directory is part of our ongoing series of informative articles for Linux enthusiasts. It features hundreds of detailed reviews, along with open source alternatives to proprietary solutions from major corporations such as Google, Microsoft, Apple, Adobe, IBM, Cisco, Oracle, and Autodesk. You’ll also find interesting projects to try, hardware coverage, free programming books and tutorials, and much more. Know a useful open source Linux program that we haven’t covered yet? Let us know by completing this form. |
Hi, where is weka?
It features in our Data Mining Group Test
https://www.linuxlinks.com/DataMining/
I have read some excellent stuff here. Definitely value bookmarking for revisiting. I wonder how much effort you put to make the sort of excellent informative website.