
Speech synthesizers are text-to-speech systems used with computers. This type of software is programmed to include phonemes and the grammatical rules of a language, so that words are pronounced correctly. A text-to-speech (TTS) system converts normal language text into speech. The reverse process is speech recognition. We cover speech recognition in a separate roundup.
Some of the tools use machine learning to massively improve the quality of the speech. Neural networks used for neural text to speech process large datasets to learn the optimal pathways from input to output. This is a form of machine learning since these networks use a neural vocoder to synthesize speech waveforms without user input. With the benefit of machine learning, software can provide strong multi-voice capabilities, and highly realistic prosody and intonation.
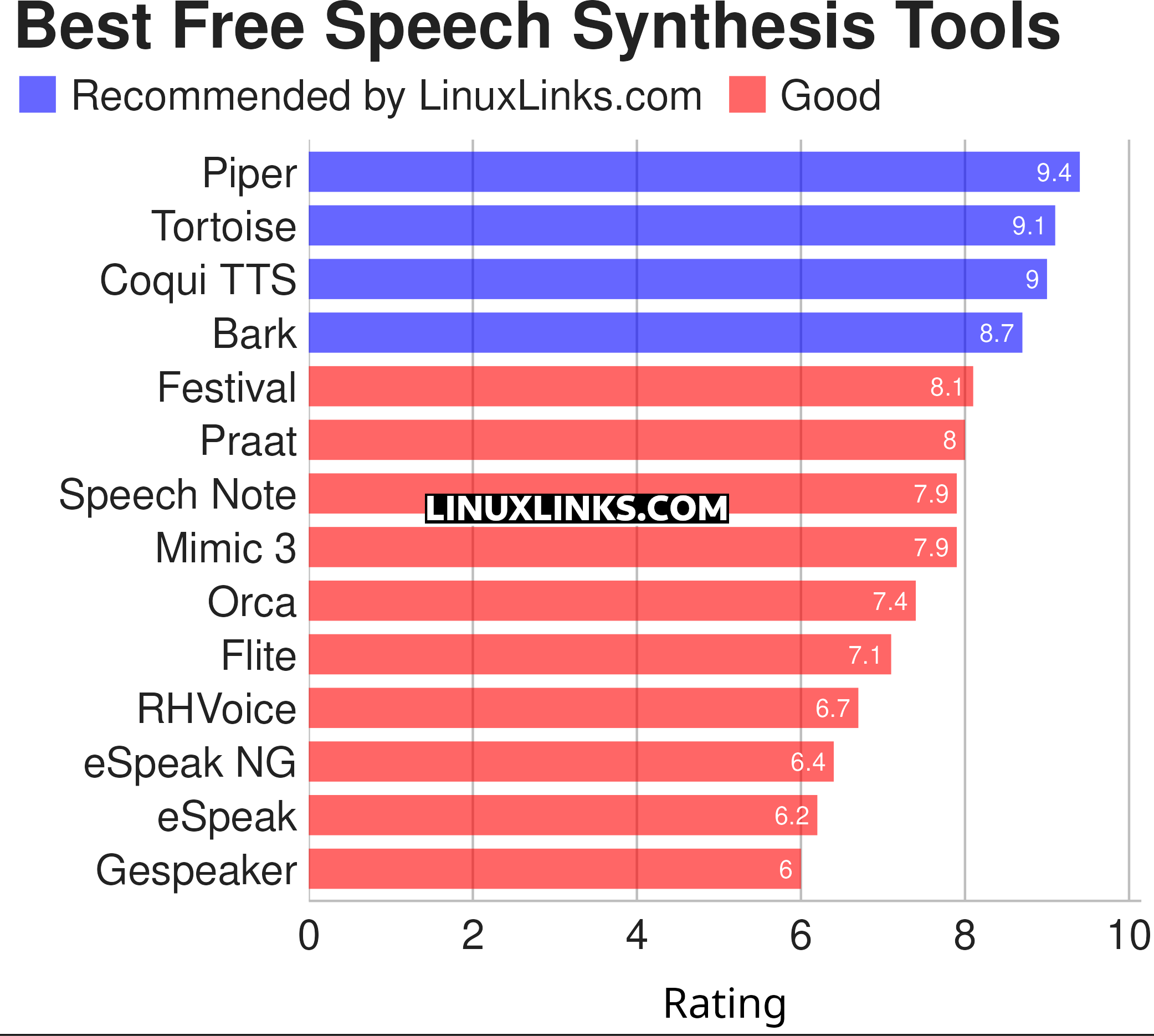
To provide an insight into the quality of software that is available, we have compiled a list of 14 useful speech synthesis tools. Here’s our verdict captured in a legendary LinuxLinks-style ratings chart. Only free and open source software is eligible for inclusion.
Click the links in the table below to learn more about each tool. We have written detailed reviews for some of the software.
| Speech Tools | |
|---|---|
| Piper | Fast, local neural text to speech system |
| Tortoise | Multi-voice text-to-speech system trained with an emphasis on quality |
| Coqui TTS | Offers pretrained models in more than 1,100 different languages |
| Bark | Transformer-based text-to-audio model. |
| Festival | General multi-lingual speech synthesis system |
| PraatSpeechAnalyser | Software for speech analysis and synthesis |
| Speech Note | Speech to Text, Text to Speech and Machine Translation |
| Mimic 3 | Lightweight Text to Speech engine |
| OrcaScreenReader | Scriptable screen reader |
| Flite | Small, fast run time text to speech synthesis engine |
| RHVoice | Gives the visually impaired a synthesis voice with their screen reader |
| eSpeak NG | Continuation of the eSpeak project |
| eSpeak | Speech synthesizer using a formant synthesis method |
| Gespeaker | GTK-based frontend for eSpeak |
This article has been revamped in line with our recent announcement.
 Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category. Explore our comprehensive directory of recommended free and open source software. Our carefully curated collection spans every major software category.This directory is part of our ongoing series of informative articles for Linux enthusiasts. It features hundreds of detailed reviews, along with open source alternatives to proprietary solutions from major corporations such as Google, Microsoft, Apple, Adobe, IBM, Cisco, Oracle, and Autodesk. You’ll also find interesting projects to try, hardware coverage, free programming books and tutorials, and much more. Know a useful open source Linux program that we haven’t covered yet? Let us know by completing this form. |
I tried using Julius and it was terrible
Probably a problem between your chair and your keyboard. Julius is, in fact, very good, with fine WebRTC-based voice activity detection.
How can you compare speech recognition (Julius) with Text to speech (espeak) ???????????
Who said they are comparative ratings?